
컴공생의 다이어리
kNN(k Nearest Neighbor) 알고리즘 본문
kNN 알고리즘이란?
kNN 알고리즘은 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘으로 거리를 측정할 때 유클리디안 거리 계산법을 사용한다.
kNN 알고리즘은 간단하지만 이미지 처리, 영상에서 글자 인식과 얼굴 인식, 영화나 음악, 상품 추천에 대한 개인별 선호 예측, 의료, 유전자 데이터의 패턴 인식 등 많은 분야에서 응용되어 사용된다.
개념
새로운 데이터가 입력되었을 때, 기존의 데이터와 새로운 데이터를 비교함으로써 새로운 데이터와 가장 인접한 데이터 k개를 선정한다. 이어서, k값에 의해 결정된 분류를 입력된 데이터의 분류로 확정한다. 즉, 새로 입력된 데이터와 기존 데이터를 비교함으로써 새로운 데이터를 유사하게 판단된 기존 데이터로 분류한다.
cf) k는 보통 홀수를 많이 사용

이제 예시를 통해서 kNN을 설명해 보겠다. 아래 그림을 보면 모든 데이터는 각각 x값과 y값이 있다. 그리고 점의 색상은 초록과 빨강으로 표시되었다. 그리고 하얀색 점은 아직 분류가 안 된 새로운 데이터이다. kNN 알고리즘의 목적은 이 새로운 하얀색 점이 등장했을 때 이걸 초록색으로 분류할지 빨강색으로 분류할지 결정하는 것이다.
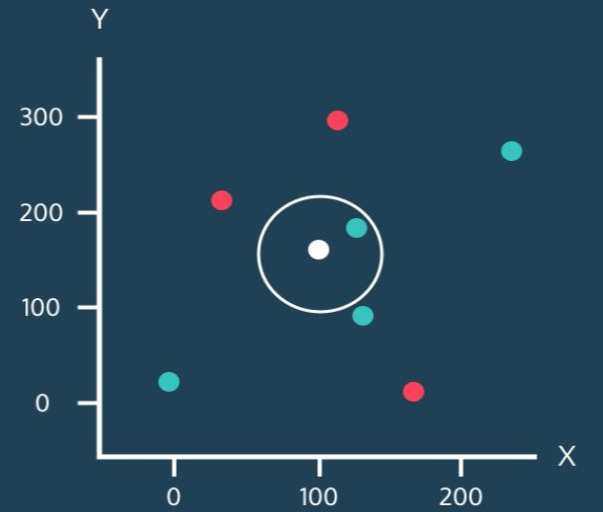
하얀점 주위를 보면 원이 그려져 있고 이 원 안에는 1개의 초록색 점이 있다. 이렇게 원 안에 포함될 이웃의 개수를 k라고 생각하면 된다. 위 그림에서 k는 1이기 때문에, 하얀점은 초록색으로 분류된다.

이번에는 k가 2일때이다. 이 경우 원 안에 있는 점 모두 초록색임으로 하얀점은 초록으로 분류된다. 만일 k가 2일 때, 원안에 있는 점이 빨간색과 초록색 점 각각 1개씩 있을 경우(=동률(tie)인 경우) 하얀점을 분류하는 기준이 애매해기 때문에 보통 k는 홀수로 설정한다. 물론 동률인 경우에도 하얀색 점을 분류할 수 있긴 하다. 예를 들어 제일 가장 가까운 점의 색을 따른다던지, 아니면 랜덤으로 색을 결정하는 방법 등이 있다.
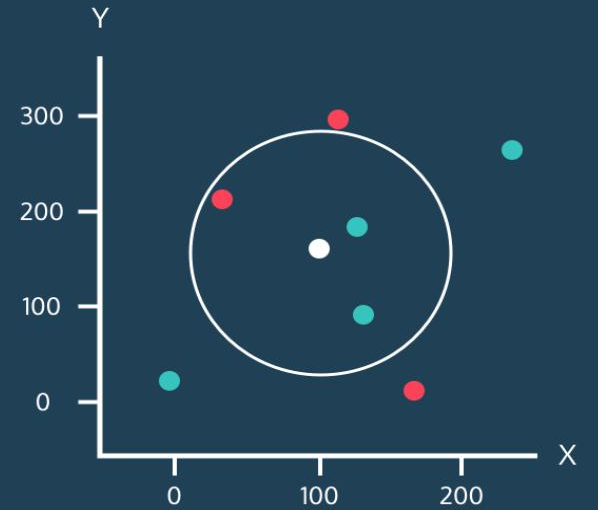
이번에는 k가 3일때이다. 이 경우 원 안에 빨간색 점 1개, 초록색 점 2개가 있으므로 하얀점은 초록으로 분류된다.
kNN 알고리즘은 어떻게 보면 일종의 다수결이라고 할 수 있다.
kNN 장점
- 기존 분류 체계 값을 모두 검사하여 비교하므로 높은 정확도를 가짐
- 비교를 통해 가까운 상위 k개의 데이터만 활용하기 때문에 오류 데이터는 비교대상에서 제외
- 기존 데이터를 기반으로 하기 때문에 데이터에 대한 가정이 없음
kNN 단점
- 기존의 모든 데이터를 비교해야 하기 때문에 데이터가 많으면 많을 수록 처리 시간이 증가 => 느린속도
- 많은 데이터 활용을 위해 메모리를 많이 사용하게 되어 고사양의 하드웨어가 필요
머신러닝 이론 및 파이썬 실습 - 인프런 | 학습 페이지
지식을 나누면 반드시 나에게 돌아옵니다. 인프런을 통해 나의 지식에 가치를 부여하세요....
www.inflearn.com
hleecaster.com/ml-knn-concept/
K-최근접 이웃(K-Nearest Neighbor) 쉽게 이해하기 - 아무튼 워라밸
본 포스팅에서는 머신러닝에서 사용할 K-최근접 이웃(K-Nearest Neighbor)에 대한 개념 설명을 최대한 쉽게 설명한다. 정규화(normalization), k개수에 따른 과적합(overfitting), 과소적합(underfitting)에 대한
hleecaster.com
'데이터 분석 & 머신러닝' 카테고리의 다른 글
| 베이즈 정리(Bayes Theorem) (0) | 2021.01.09 |
|---|---|
| 확률(Probability) (0) | 2021.01.09 |
| 엔트로피, 정보이득 계산과 ID3알고리즘 (0) | 2021.01.09 |
| 불순도(Impurity)와 엔트로피(Entropy) (3) | 2021.01.08 |
| 의사결정트리(Decision Tree) (0) | 2021.01.08 |



